实际工作中,大部分项目和业务都是读多写少
为了保证高可用性,提升读速度,一般会采用读写分离、一主多从的数据库架构
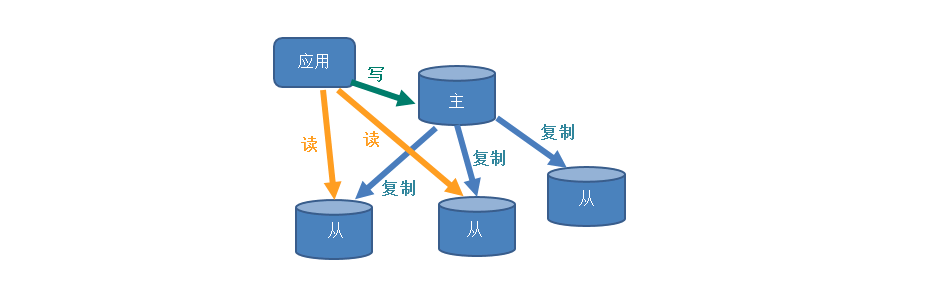
但是主从同步是延时的,如果在写操作同步完成前发生了读操作,就会导致脏读,如何解决🧐
半同步复制
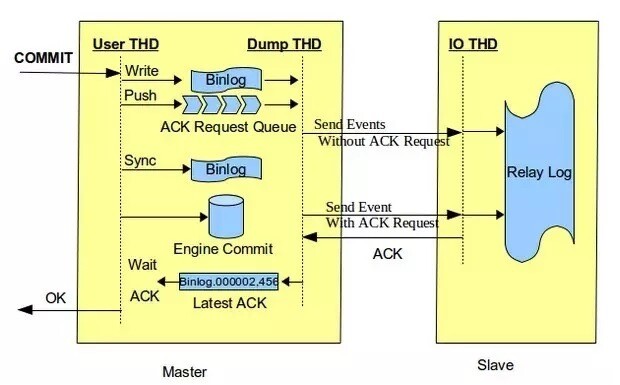
普通的主从同步是使用 MySQL 的异步复制,依靠二进制日志(binary log)进行
从 5.5 版本开始,MySQL 引入了半同步复制(semi-sync):一个事务提交时,日志至少要保证有一个从接收到,那么它的提交才能继续
- 系统先对主库进行了一个写操作
- 等主从同步完成,写主库的请求才返回
- 读从库,读到最新的数据(如果读请求先完成,写请求后完成,读取到的是“当时”最新的数据)
这个方案的优点是原生功能,使用简单
在线加载插件安装:
1 | mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so'; |
写入配置文件:
1 | [mysqld] |
缺点是主库的写请求时延会增长,吞吐量会降低
强制读主库
如果读写都到主库,就不会出现这种问题了。需要使用缓存来弥补缺失的读性能。
数据库中间件
- 所有的读写都走数据库中间件,通常情况下,写请求路由到主库,读请求路由到从库
- 记录所有路由到写库的 key,在经验主从同步时间窗口内,如果有读请求访问中间件,此时有可能从库还是旧数据,就把这个 key 上的读请求路由到主库
- 经验主从同步时间过完后,对应 key 的读请求继续路由到从库
ShardingSphere-JDBC
apache/shardingsphere 是当当应用框架 ddframe 中,从关系型数据库模块 dd-rdb 中分离出来的数据库水平分片框架
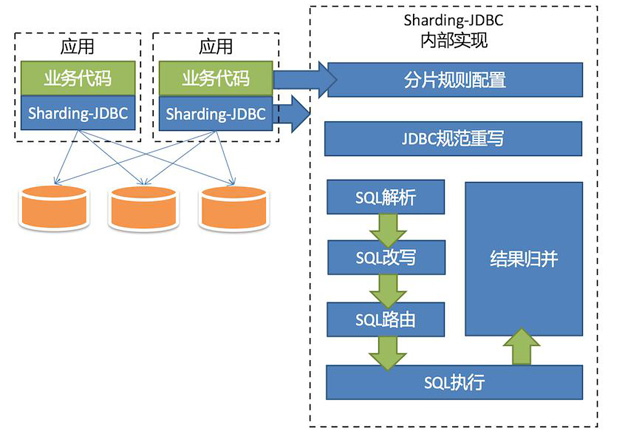
以 jar 包形式提供服务
分片灵活,支持等号、BETWEEN、IN 等多维度分片
SQL 解析,支持聚合、分组、排序、LIMIT、OR 等
Mycat
社区爱好者在阿里 Cobar 基础上进行二次开发,解决了 Cobar 的一些问题,且加入了新的功能
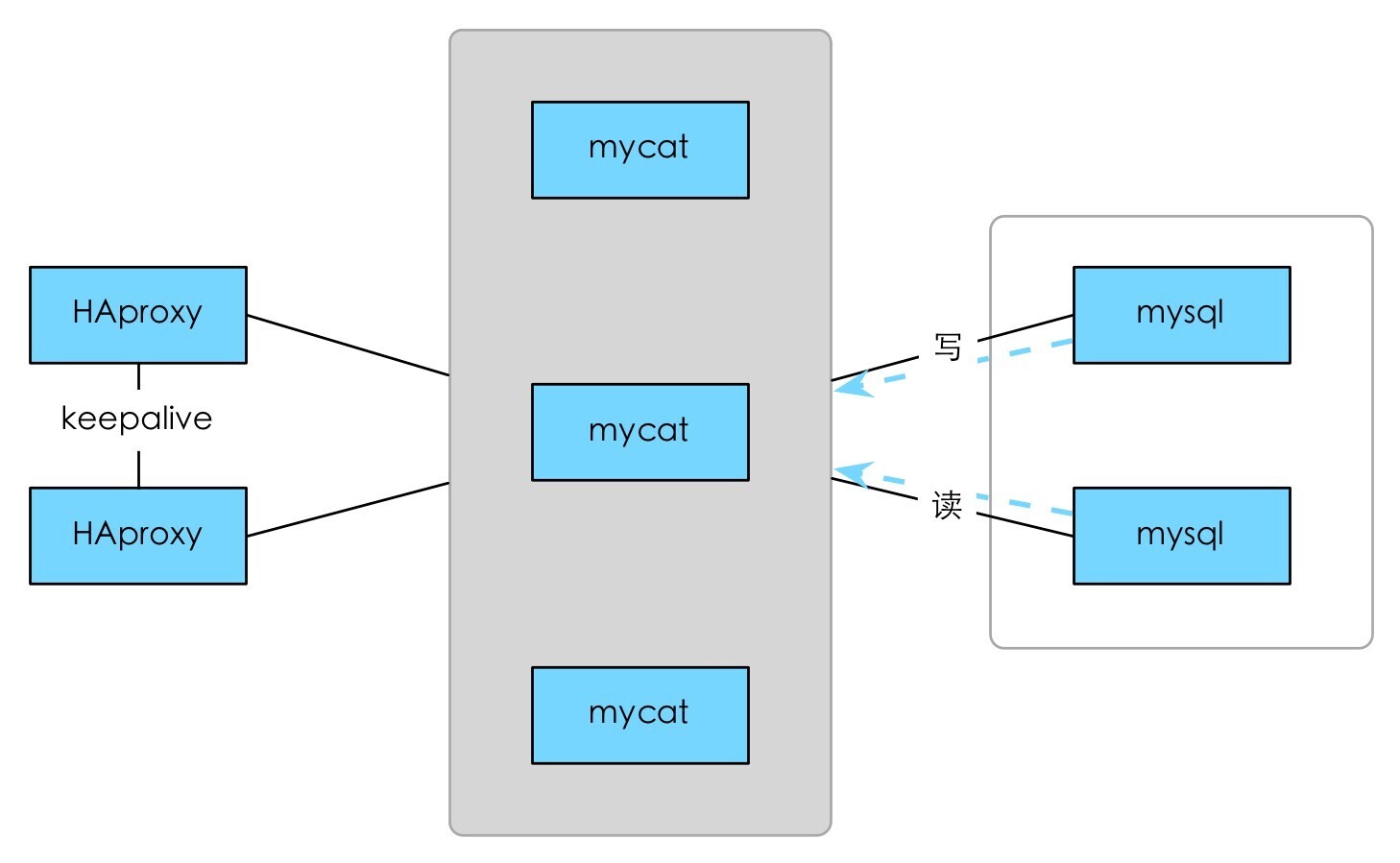
遵守 MySQL 原生协议
基于心跳的自动故障切换
支持读写分离,支持主从
支持 SUM、COUNT、MAX 等聚合,支持跨库分页
支持服务降级
安全,IP 白名单、SQL 注入攻击拦截、prepare 预编译
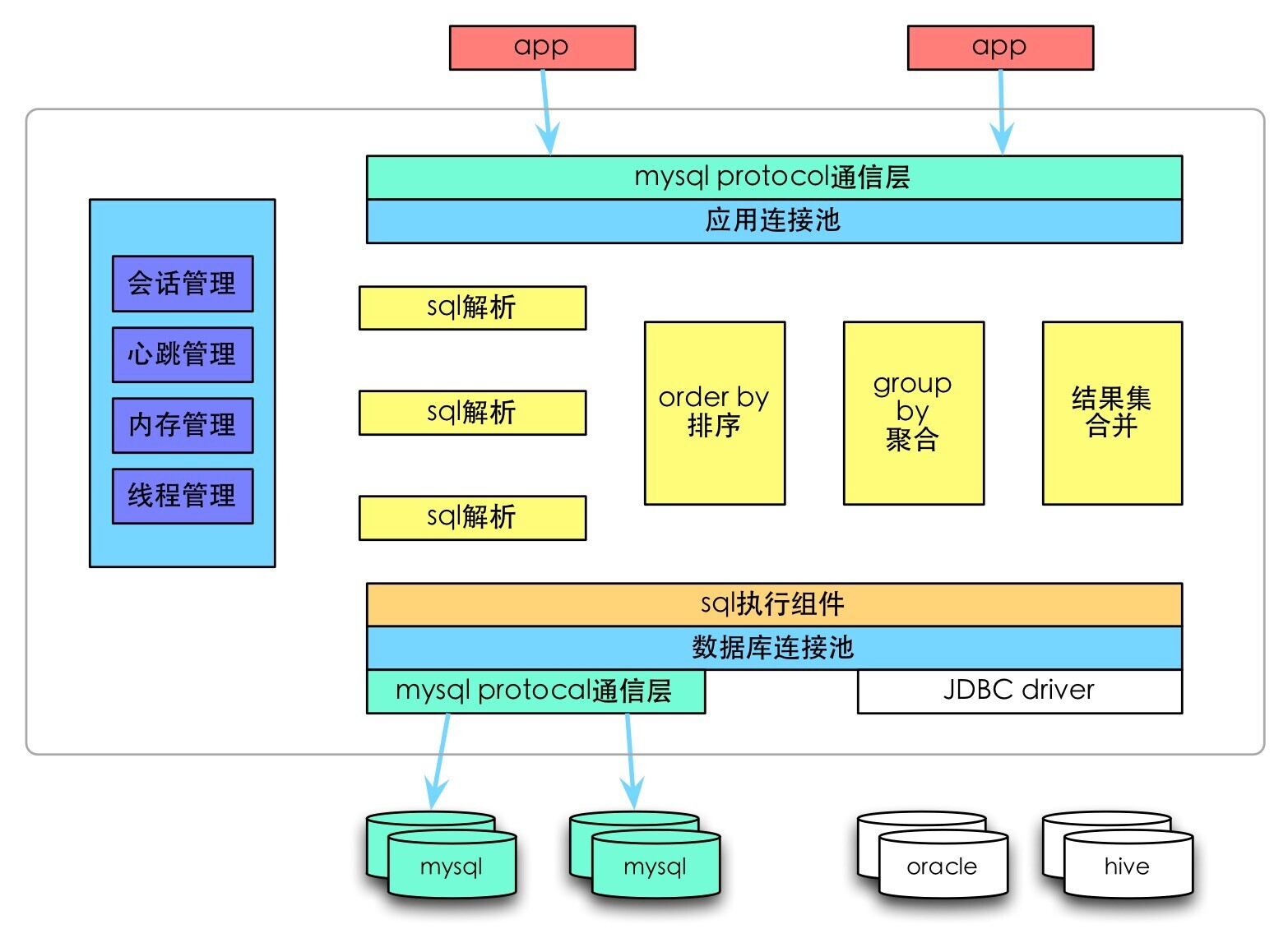
DBproxy
针对 Atlas 进行改进,形成了新的高可靠、高可用企业级数据库中间件 DBProxy
读写分离
负载均衡
slave 故障感知&摘除
连接池
自定义 SQL 拦截&过滤
流量分组&控制
监控状态
其它
Atlas:360 团队基于 MySQL Proxy 把 Lua 用 C 改写,在高并发下会挂掉
OneProxy:基于 MySQL 协议的数据库中间件。C 开发,专注于性能和稳定性。闭源
Vitess:Youtube 生产使用,架构复杂,使用改动大
Cobar:阿里 B2B 开发的关系型分布式系统,后面无人维护
想自主开发的话要看公司技术实力,时间人力成本都相当高
使用市场上的中间件也要注意信息安全
缓存记录写 key
最后说的这个方案总结了前三个方案的优缺点,就是用缓存记录库中操作的 key:
- 写
- 某库的某 key 要进行写操作,把它记录到缓存里,设置好超时时间(比主从同步的时间大点)
- 进行写操作
- 读
- 查询缓存,本次读操作的 key 是否在缓存里
- 缓存命中,将本次读操作路由给主库,查新数据
- 缓存未命中,依旧从库处理
这个方案成本低,付出的代价是在读写时都多了一步缓存操作