最近需要做个统计,计算一个销售或部门(n 个销售),在一段时间内(n 天)的成交数据

每个销售每天一条记录(si_id 和 date 组合索引),data 数组存放了每个产品的成交数量
简单分析后,我们需要得到的就是 data 下每个 product_id 的 num 之和
在查询出来后,进行循环处理,结果由于数据量太大导致内存溢出。能不能像 MySQL 中直接进行 GROUP BY + SUM() 呢?
数据在 Mongo,大致结构如下:
1 | [ |
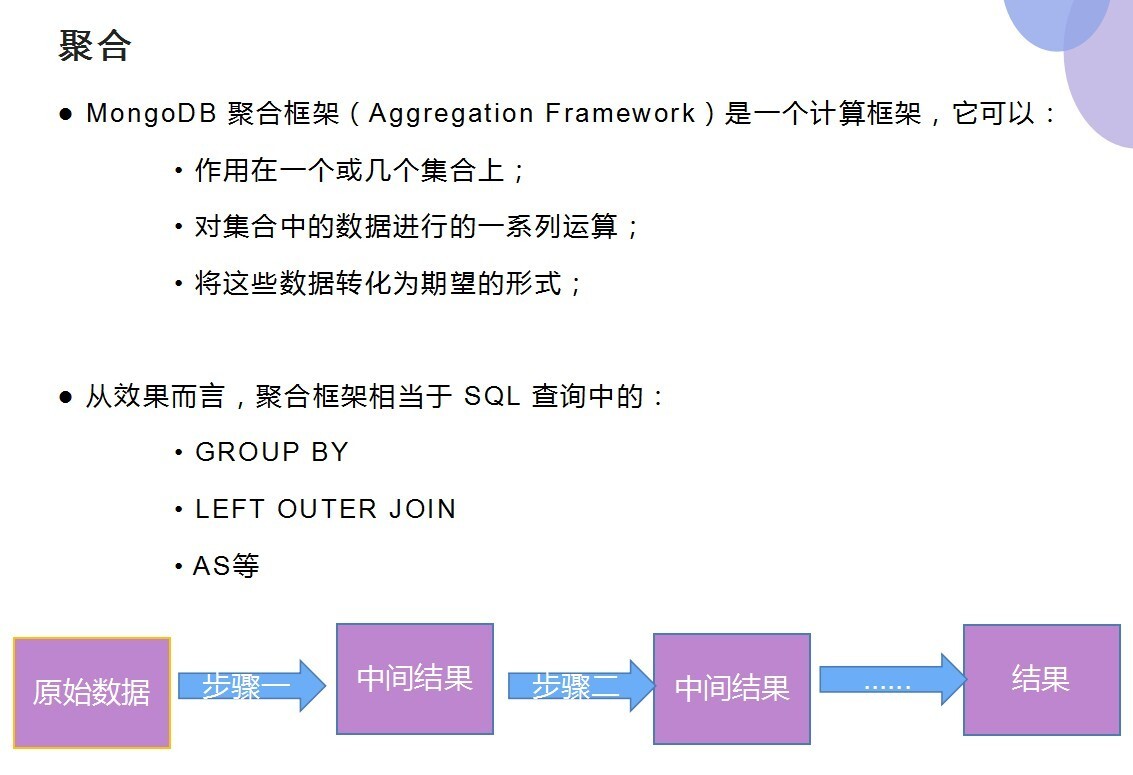
查看文档后发现了 Mongo 的聚合 Aggregation,其中有几种实现方式

这里分享的是管道方式,Map-Reduce和单用途聚合可以查看官方文档
管道模式顾名思义就是像个 pipeline 一样,经过层层筛选,最终得到你想要的结果
第一阶段
首先使用 $match 添加查询条件,把销售 ID 条件和 时间条件写上:
1 | [ |
第二阶段
如果需要,使用 $project 指定查询列,例如我们想分次查,一次求一个产品的和:
1 | [ |
由于我们的数据结构特殊,需要处理数组,所以要加上 $unwind
1 | [ |
第三阶段
使用 $group 进行求和,也就是我们需要的结果:
1 | [ |
意犹未尽的你可以再去看看文档,是否能进一步优化你的日常开发
| 步骤 | 作用 | SQL等价运算符 |
|---|---|---|
| $match | 过滤 | WHERE |
| $project | 投影 | AS |
| $sort | 排序 | ORDER BY |
| $group | 分组 | GROUP BY |
| $skip/$limit | 结果限制 | SKIP/LIMIT |
| $lookup | 左外连接 | LEFT OUTER JOIN |
see MongoDB\Collection::aggregate()