高可用(High Availability,简称 HA)主要是指通过设计减少系统不能提供服务的时间,来提高系统的可用性。其主要目的是为了保障业务的连续性,确保在用户眼里,业务永远是正常(或者说基本正常)对外提供服务的
高可用主要是针对架构而言,要做好高可用,就要设计好架构,包括应用层、中间件、数据存储层等独立的层次,并且要保证架构中所有组件以及其对外暴露服务都要做高可用设计。任何一个组件或其服务没做高可用,都意味着系统存在风险
高可用性的实现主要依赖于冗余和自动故障转移。冗余意味着系统组件一般以集群的形式存在,当某台机器出现问题时,集群中的其他机器可以随时顶替。而自动故障转移则是通过第三方工具的力量来实现故障的自动转移,以达到近实时的故障转移效果,这是高可用的主要意义
业界通常用几个九来衡量系统的可用性,比如四个九(99.99%)的系统可用性指标表示该系统在所有运行时间中只有 0.01% 的时间是不可用的。要达到这样的高可用性,系统需要具有自动恢复能力,不能仅依靠人工运维方式实现
业务需求
北森 iTalent 是我们公司采购的一个人力资源管理平台,它也是我们人事数据的来源,提供了时间窗接口来让我们获取 CUD 的数据(员工、部门、职位等的增/删/改)。
盖雅工场是公司采购的另一个系统,用来做考勤。
因为公司的大半都是门店员工,考勤规则非常复杂,希望通过盖雅来解放算薪的人力
现在需要从北森获取到变更的数据后,再生成文件发到盖雅服务器里。
开始想把修改数据放内存中,然后直接写到对方文件里,但这样不够稳妥
决定在本地记录一份和目标一样的副本
业务背景
当时人力总监考察了市面的系统后,发现只有盖雅能够支持我们的复杂逻辑,咱受对方蛊惑,听信了对方是考勤业界的王。

盖雅工场需要咱将员工与部门数据同步给他们,这看起来并不是啥麻烦事,我原本是这样以为的。
开幕雷击,可能还是我见的世面少了,系统对接使用文件传递,需要以 csv 文件方式将员工的增量数据放进他们的服务器。
通过询问后知道,他们每次对接都是这样,都是进行定制开发(表头不一致),没有统一的处理方案。
实现方案
先把数据在本地写好,再通过已有的服务来传过去
一个Golang接收文件的尝试
Go(又称Golang)是 Google 开发的一种静态强类型、编译型、并发型,并具有垃圾回收功能的编程语言
罗伯特·格瑞史莫(Robert Griesemer),罗布·派克(Rob Pike)及肯·汤普逊(Ken Thompson)于 2007 年 9 月开始设计 Go,稍后 Ian Lance Taylor、Russ Cox 加入项目
Go 是基于 Inferno 操作系统所开发的,于 2009 年 11 月正式宣布推出,成为开源项目,并在 Linux 及 Mac OS X 平台上进行了实现,后来追加了 Windows 系统下的实现
在 2016 年,Go 被软件评价公司 TIOBE 选为“TIOBE 2016 年最佳语言”

由于公司已经有个 Golang 实现的 SFTP 下载文件的服务,所以在它的基础上增加了上传功能
1 | func (s *Server) Upload(w http.ResponseWriter, r *http.Request) { |
它的核心是接收文件名参数,在本地打开并复制到对方服务器的指定位置
1 | srcFile, _ := os.Open(fileName) |
这肯定实现不了我们的需求,要把文件内容给发过来,所以改成了 POST 表单的方式
1 | Storage::put($filename, $fileContent); |
在 Golang 中接收有多种写法
1 | file, handler, err := r.FormFile("xxx") |
这时 Golang 返回了一个错误:multipart: NextPart: EOF
在搜索解决方案时,都说是请求头不对,不要加
但是这个请求头是 GuzzleHttp 自己生成的,我手动改写后又返回了其它错误,例如 no multipart boundary param in Content-Type
我想,这种不行就换种吧,直接整个 body 放文件流
1 | $response = (new Client())->post($this->apiUrlRoot.'/upload', [ |
在 Golang 中把请求放入文件
1 | _, _ = io.Copy(dstFile, r.Body) |
再经过一次次的测试后,目标文件总是空的,打印请求的内容也是
陷入沉思,到底是哪出了问题(滑稽,所以在两种方法间横跳
回到表单方法,发到本地测试的 PHP 服务上,打印 $_FILES,成功显示
然后在网上各种搜 Golang 上传文件的例子看,也没看出有啥区别,所以就请教了公司大佬
我们一起排查问题,定位到是 URL 的问题,Go web server is automatically redirecting POST requests
由于在拼接地址时,多了一个 /,客户端使用 //upload POST 请求,Golang 会响应 301 到 /upload,并转为 GET 请求,不会重新发送 Body
用SFTP传个文件
测试一会之后,发现不用这么麻烦,改用 PHP 项目自己解决传递,一个是减少了影响项目,另一个是利于维护。
SFTP 全名 SSH 文件传输协议 Secret File Transfer Protocol,是一种数据流连线档案存取、传输和管理功能的网络传输协议
与 FTP 相比,SFTP 使用了加密技术,保证了数据在传输过程中的安全性。同时,SFTP 也提供了丰富的文件操作功能,如文件上传、下载、删除等
因此,SFTP 被广泛应用于各种需要安全文件传输的场景,如远程服务器备份、数据同步等
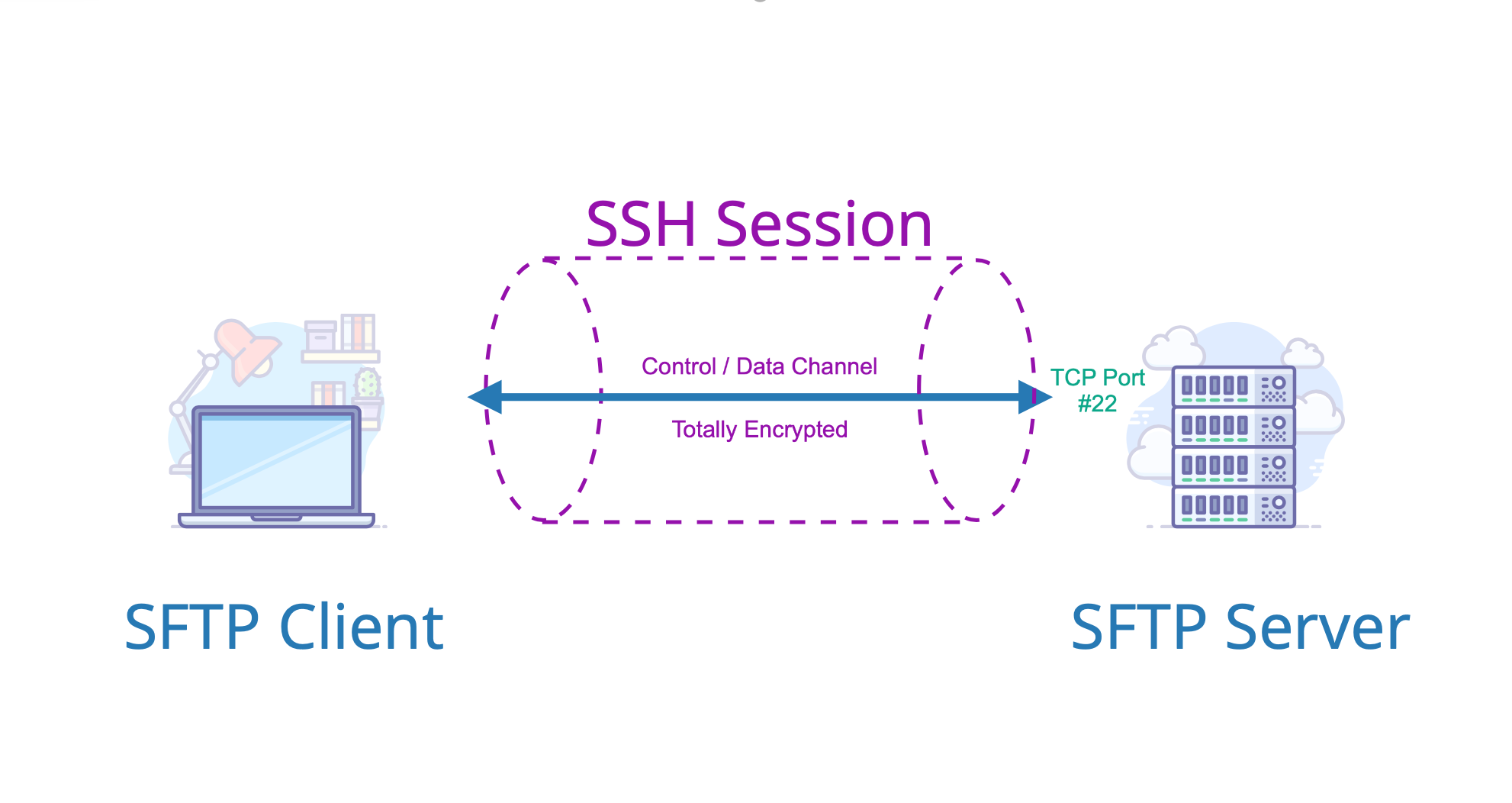
使用 SFTP 进行文件传输前,需要进行登录操作。SFTP 登录过程包括以下步骤:
客户端向服务器发起连接请求,指定服务器的 IP 地址和 SFTP 端口号(默认为 22)
服务器收到连接请求后,会向客户端发送 SSH 协议的密钥,用于建立加密连接
客户端使用 SSH 协议对服务器进行身份验证,验证成功后,会创建一个安全的加密通道
在安全通道上,客户端使用 SFTP 协议进行文件传输
PHP 使用 SFTP 发送文件
1 | $connection = ssh2_connect($this->host, $this->port); |
惊讶的是同一份代码在测试服务器上正常运行,在对方的服务器上 SCP 就报错
ssh2_scp_send(): Failure creating remote file: (-28)
而用 IDE 自带的远程管理登录后,读写权限都是正常的
这神奇的 BUG 体质,又该请教大佬了,通过命令行测试:
1 | scp -v -P whichPort localFile whoYouAre@address:remoteFile |
改用 sftp 命令连接上再写文件是正常的,所以代码修改为
1 | $sftp = ssh2_sftp($connection); |
Laravel File Storage
Laravel 内置了 Flysystem 扩展包,能够使用简单的 API 来操作,未来需要更换驱动时也方便
在使用 SFTP 前需要下载依赖 league/flysystem-sftp ~1.0
在配置文件中增加此 “磁盘” 的配置:
1 | 'disks' => [ |
使用门面来获取实例,以获取文件夹内所有文件名为例:
1 | $remoteDisk = Storage::disk('remote'); |
上面的业务逻辑通过简单的 2 个方法就能完成:
1 | Storage::disk('remote')->put($filename, self::TABLE_HEADER . PHP_EOL); |
后续维护
但背景是目前的员工数量已经达到了 7k,全量文件不小
先把增量员工查出来,再把数据切割成 csv 格式的字符串,写入文件。会出现如下问题:
- 频繁使用远程连接会出现失败
- 全量时接口会超时
- 偶发的内容拼接错误(某一行出现在上一行的中间部分,其它行正常)
第一步考虑用队列先解决数据量大的问题,先优化为:把需要同步的拆分为每 100 一批放入队列,把数据转换为 csv 的一行内容后,先写入本地文件,再把整个本地文件内容复制到远程。
但是用的队列是多个同时消费,最后的结果没有按需要的顺序,并且需要区分每一个内容是属于哪次文件,在单次文件全部结束后再传递到服务器。
改用可用性更高的数据库方式来解决:新建一张表,用来存储员工在文件中对应的一行内容,再新增一个 Laravel Listener,在员工进行 CUD 时就新增或修改到新表中,定时任务再通过时间戳去查询。
此时把内容数组存在表中的 JSON 字段时,再取出来放到文件中时,顺序会错乱,是因为 MySQL 在存储 JSON 时按照 KEY 的字段长度做了排序,以便获得更好的存储性能:see JSON比较
To make lookups more efficient, it also sorts the keys of a JSON object. You should be aware that the result of this ordering is subject to change and not guaranteed to be consistent across releases.
所以就把内容字段类型改为 TEXT,切割好了再存进去,取的时候拼个换行符就能用了。这样子就不会出现多次进行远程连接,也留下了可以排查问题的记录。
业务进展
因为对方是定制化开发,需要重新做,这样就导致我们的进度是完全依赖于对方的,就算我们是甲方,也没有说能百分百控制住关键时间点。咱们的业务分与对方沟通了数次之后,终于确定好了各字段内容的格式。
业务方偶尔反映数据有问题,这时没有一个判断依据,因为对方每次处理完文件后都会删除掉,我们的文件也在容器里。
更窒息的是对方没有错误提示,要登录服务器才知道同步因为报错卡住了!就很好奇这样的方式之前没人吐槽过吗。
并且他们的逻辑是一个文件里遇到一行错误,剩下的就不执行了,而且之后的新文件也不执行了
对方也是急需吃下我们这个大单,再经过很多次的反馈后,对面逐渐重视,由领导来牵头解决了对接中的一些情况。经过我们持续优化后,终于保证了整个业务高可用。
上线后,由于之前员工都习惯了钉钉打卡,改用盖雅的 H5 后不熟悉,并且 UI 简直是十几年前的画风。我方提出了几点来兼容使用习惯,例如增加查看打卡记录的入口、自动打卡、修改 UI 等,又需要对方进行排期与估价。一点小修改开出了 18w 的报价,所以我们决定自己出 UI,让他们直接替换掉。
“业界领先”的系统连很多基础功能都没有
经过几个月的折腾才完成了整个计划的前奏,关键的目标是用对方提供的考勤数据来计算薪资,所以咱还得接着开发。
果不其然,整个数据又是放在他们服务器,让我们去取。但是直到上线,对方都没有保证每个月什么时间点能生成好数据。
现在回头看看最初的目标,由于对方生成的文件数据并不准确,还是没有解决算薪的问题,需要花整个部门(三支柱的SSC)的几天通宵去验证对方数据准确性。
延伸阅读

人力资源三支柱模型是由 COE(专家中心)、HRBP(人力资源业务伙伴)和 SSC(共享服务中心)三个职能构成的人力资源体系
这一模型是戴维·尤里奇在 1997 年提出的,旨在基于公司战略服务于公司业务,通过组织能力再造,让 HR 更好地为组织创造价值
COE 主要负责制定总体的人力资源战略、政策、流程、体系、方案等,是政策中心层
HRBP 负责以 HR 专业角度发现业务运行问题,提出建议,是更基于业务导向的人力资源解决方案提供和执行者
SSC 则负责日常操作事务类工作,是标准化的服务提供者
人力资源三支柱模型与人力资源六大模块的关系在于,三支柱模型是基于六大模块(招聘、培训、薪资福利、绩效、员工关系等)的纵向工作方式进行划分,即从制定战略——执行——基础事务的流程进行划分。这种模式相较于传统的按专业职能划分的人力资源组织架构,更注重于组织能力的再造和提升,以适应企业战略和业务发展的需求
整理总结
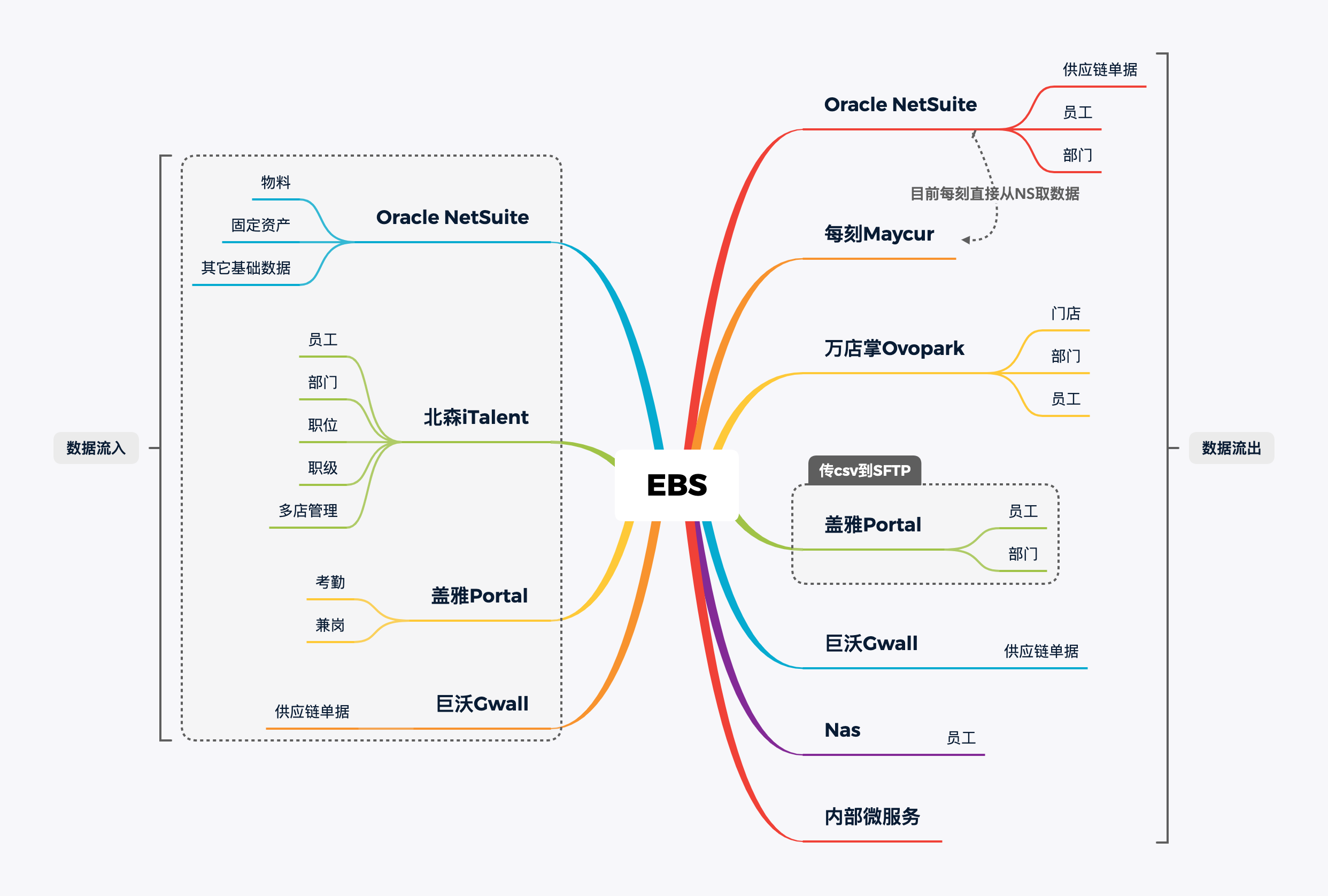
由于公司选择依赖市面上成熟的系统,例如钉钉、每刻报销、万店掌监控等,在对接各公司时有很多麻烦的地方。
以组织架构数据为例:
- 从北森接口定时获取增量数据
- 将每一条数据放入 Job 处理,基于阿里云 MQ
由于公用一个实例,出现偶发堵塞
- 触发 Laravel 事件
event() - 根据配置的 Listener,把数据传入各个业务线
各条线接口的日志是分表存数据库里,查询效率低
例如CONVERT(parameters using 'utf8') LIKE '%123456%'
总结出如下需要改进的点:
- 由于各业务线都有需要存储的业务数据,表的设计比较混乱
- 需要回调让外部请求时,缺少鉴权
- 对接外部的流程不统一,非常依赖对方的进度
- 缺少网关层的其它功能:限流、熔断等