缓存失效的三大祸害:穿透、击穿、雪崩及应对策略详解
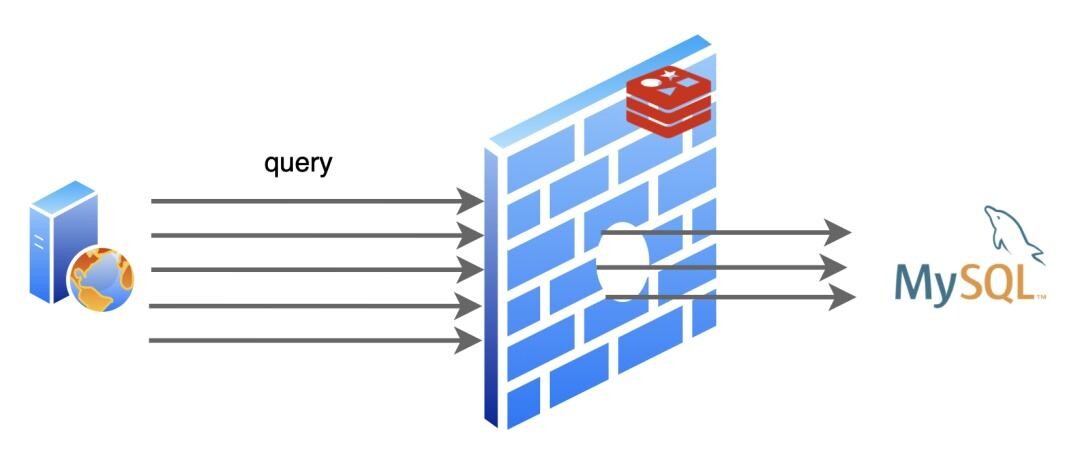
穿透
访问透过缓存直接经过数据库层,通常是一个不存在的 key,在数据库查询为空
像这样每次请求都落在数据库、并且高并发,导致数据库扛不住挂掉
解决方案:
- 将查到的 null 设成该 key 的缓存对象
- 明显错误的 key 在逻辑层验证
- 分析用户行为,是否为恶意请求或者爬虫,针对用户访问做限制
击穿
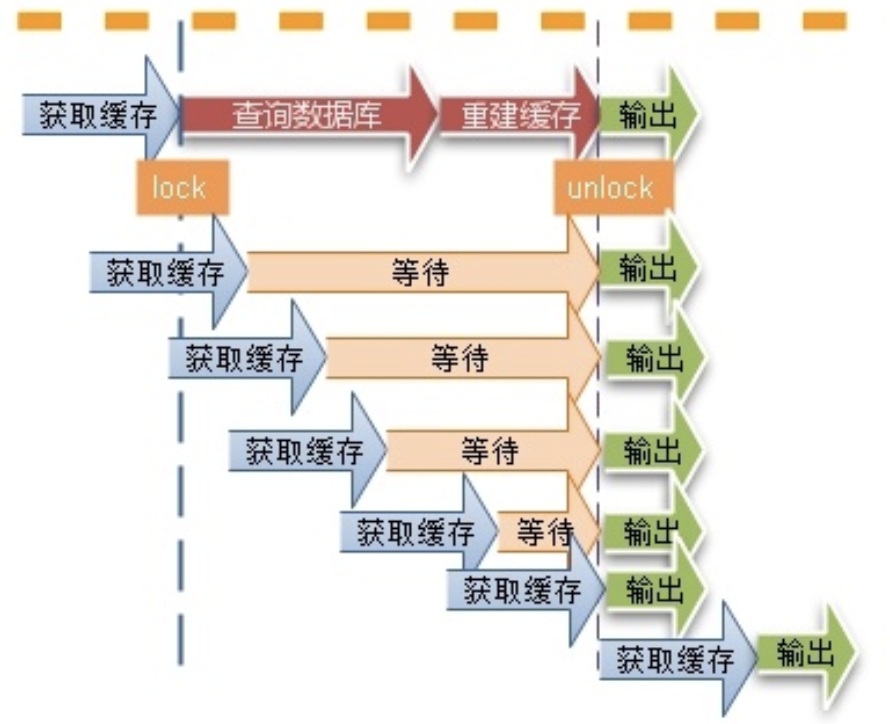
一个 key 非常热点,在不停的扛着大并发,集中对这一个点进行访问
当这个 key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,好像蛮力击穿一样
解决方案
- 可以使用互斥锁避免大量请求同时落到数据库
- 部分情况下可以将缓存设置永不过期
- 做好熔断、降级,防止系统崩溃
雪崩
缓存集体大规模集体失效,在高并发情况下突然使 key 大规模访问数据库
解决方案
- 将 key 的过期时间后面加上一个随机数,让 key 均匀的失效
- 用队列或者锁让程序执行在压力范围之内,可能会影响并发量
- 热点数据可以不失效
分布式缓存
想必在大家的架构中,Redis 已经是一个必不可少的部件,丰富的数据结构、超高的性能以及简单的协议,让它能够很好的作为数据库的上游缓存层
正是人们大量使用 Redis,逐渐暴露了一些缺点:
- 单节点物理内存有限,不能满足日益增长的业务内存的需要
- 不能提供高可用服务。节点挂掉或者该节点机器宕机,导致大量请求走向数据库,造成数据库压力增大,加大数据库宕机风险
- 运维为每个业务方创建一个节点,各业务方内存分配不均匀;机器部署杂、多,请求入口多,运维管理复杂、难以维护等
于是,人们将目光投向了分布式存储。市面上的分布式存储主要包括两大类:
- 在服务端做的分片,由运维手动给服务端每个实例分槽,服务端再根据请求的 key 所对应的槽找到对应的机器
代表服务 redis-cluster - 在客户端和服务端之间做一层代理服务,由代理服务根据一致性 hash 算法将请求路由到指定机器
代表服务 twemproxy 和 codis。
问题提出
集群服务相比较单点有了很好的扩展性,但是在使用过程中,弊端逐渐凸显(以 codis 为例):
业务方混用。所有的业务方都混用一个集群,只要有一个业务方有不当使用,造成集群处理速度变慢,其他业务方都会受影响
key 冲突。在混用同一个集群时,会有 key 冲突隐患
集群快速恢复难。直接关闭业务方服务不现实,需要一个集群服务能够快速降级
不设置缓存时间,导致随着时间的增长,无用的 key 越来越多,占用大量内存
连接数过大。线上大家在用同一个集群时,如果有一个业务方不靠谱,占用了集群所有的连接,导致系统异常
以上部分问题不是说一定会导致出现严重后果,但这些是安全隐患,而且一直存在,根据墨菲定律,这种隐患肯定会在以后发生
而且很难通过运维规范来阻止这类事情的发生,这就迫切需要一个能解决上述问题的服务来替代市面上的集群

解决思路
针对以上问题,我们新开发一个服务,有如下亮点
针对混用问题,建两个子集群,业务方 A 和 B 分别属于 group1 和 group2,这样业务方是物理隔离,如果 A 出了问题,不会影响业务方B
针对扩容问题,搭建一个新的子集群。比如子集群 group1 快要用完了,我们可以搭建 group2,而且搭建和使用都不会影响 group1 里面的业务
针对 key 冲突问题,给每个业务方分配一个 source 作为业务方每个请求 key 的前缀,如
{source}&key针对命令乱用问题,给每个业务方分配请求 redis 的命令,未分配的命令禁止使用
针对集群难以恢复和连接数占用严重,我们在内部平台中快速降级或限制
针对业务方不设置缓存失效时间问题,可以让业务方请求的 key 强制失效
打印日志并接入报表,在 Kibana 上查看