
随着移动互联网的兴起、开放合作思维的盛行,不同终端和第三方开发者都需要大量的接入企业核心业务能力,此时各业务系统将会面临同一系列的问题,例如:如何让调用方快速接入、如何让业务方安全地对外开放能力,如何应对和控制业务洪峰调用等等
于是就诞生了一个隔离企业内部业务系统和外部系统调用的屏障 - API 网关,它负责在上层抽象出各业务系统需要的通用功能,例如:鉴权、限流、ACL、降级等
另外随着近年来微服务的流行,API 网关已经成为一个微服务架构中的标配组件
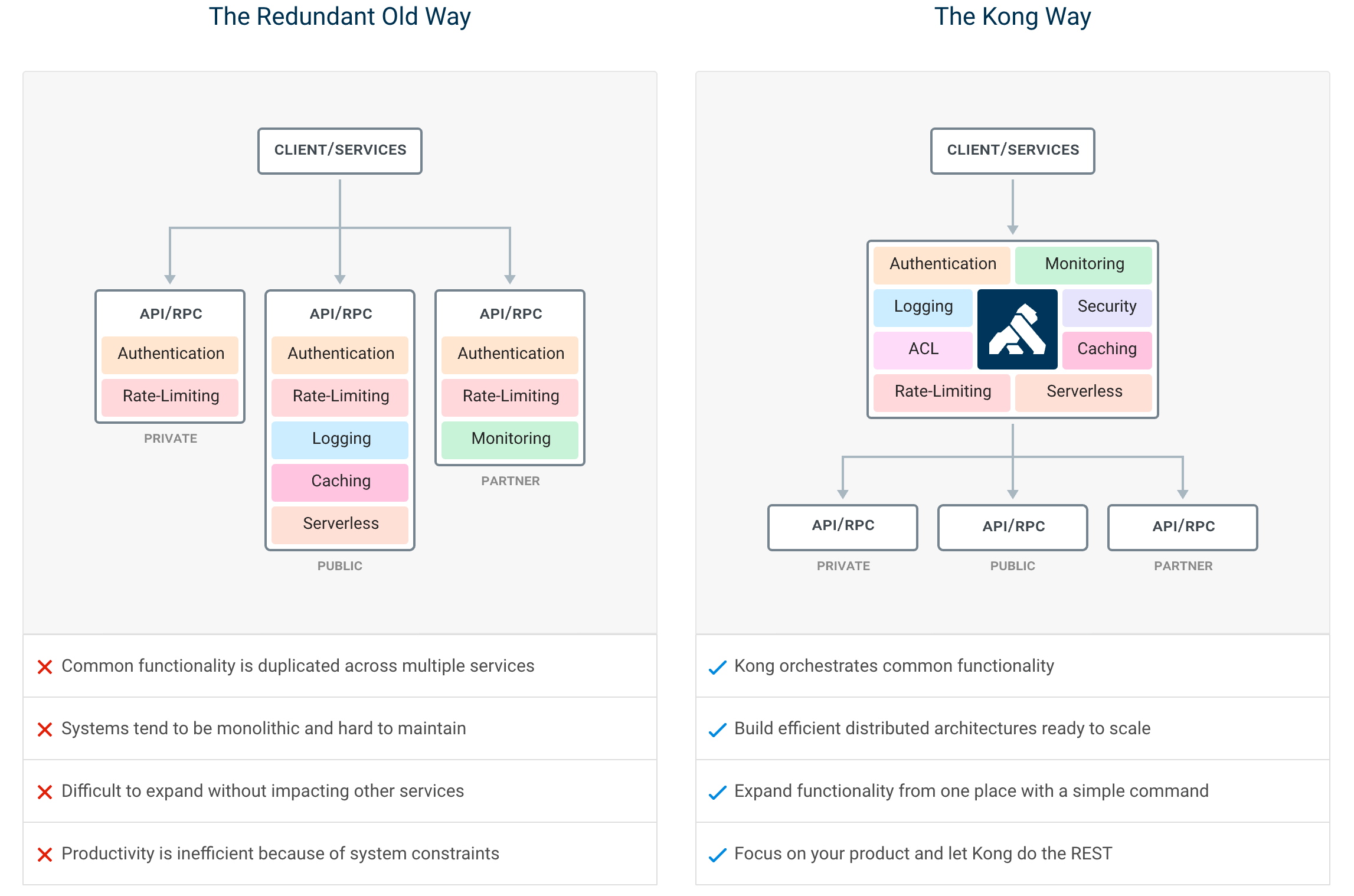
在微服务架构之下,服务被拆的非常零散,降低了耦合度的同时也给服务的统一管理增加了难度。如上图左所示,在旧的服务治理体系之下,鉴权、限流、日志、监控等通用功能需要在每个服务中单独实现,这使得系统维护者没有一个全局的视图来统一管理这些功能。API 网关致力于解决的问题便是为微服务纳管这些通用的功能,在此基础上提高系统的可扩展性。如右图所示,微服务搭配上 API 网关,可以使得服务本身更专注于自己的领域,很好地对服务调用者和服务提供者做了隔离。
认证中心部门提供了大量接口给外部门,非常需要这样一个网关。在选型时,放弃了 Orange,虽然它的优点有自带管理端、流量筛选和变量提取方面支持丰富,过滤统计配合配置规则比较好用,自带管理后台。但是从 2017 年 5 月开始后续没有开发,BUG 比较多。
Kong 的插件机制是其高可扩展性的根源,它可以很方便地为路由和服务提供各种插件,网关所需要的基本特性,Kong 都支持:
- 熔断 Circuit-Breaker
- 限流 Rate-limiting
- OAuth2.0: 身份验证
- 认证 Authentications: HMAC,JWT,Basic等
- 监控 Monitoring: 实时监视提供关键的负载和性能服务器指标
- REST API: 通过 RESTful API 管理
- 高性能 Performance: 背靠非阻塞通信的 Nginx
- 可扩展性 Scalability: 只需添加节点即可水平扩展
- 安全性 Security: ACL,僵尸程序检测,白名单/黑名单IP等
- 动态负载均衡 Dynamic Load Balancing:在多个上游服务之间平衡流量
- 插件 Plugins: Kong Hub 提供众多开箱即用的插件
在入手前,需要学习 OpenResty 的相关知识,还有 Lua 的语法。我看的李明江的《Nginx Lua开发实战》,内容大量搬运文档,不推荐
重点需要关注的是 11 个用户可介入阶段:
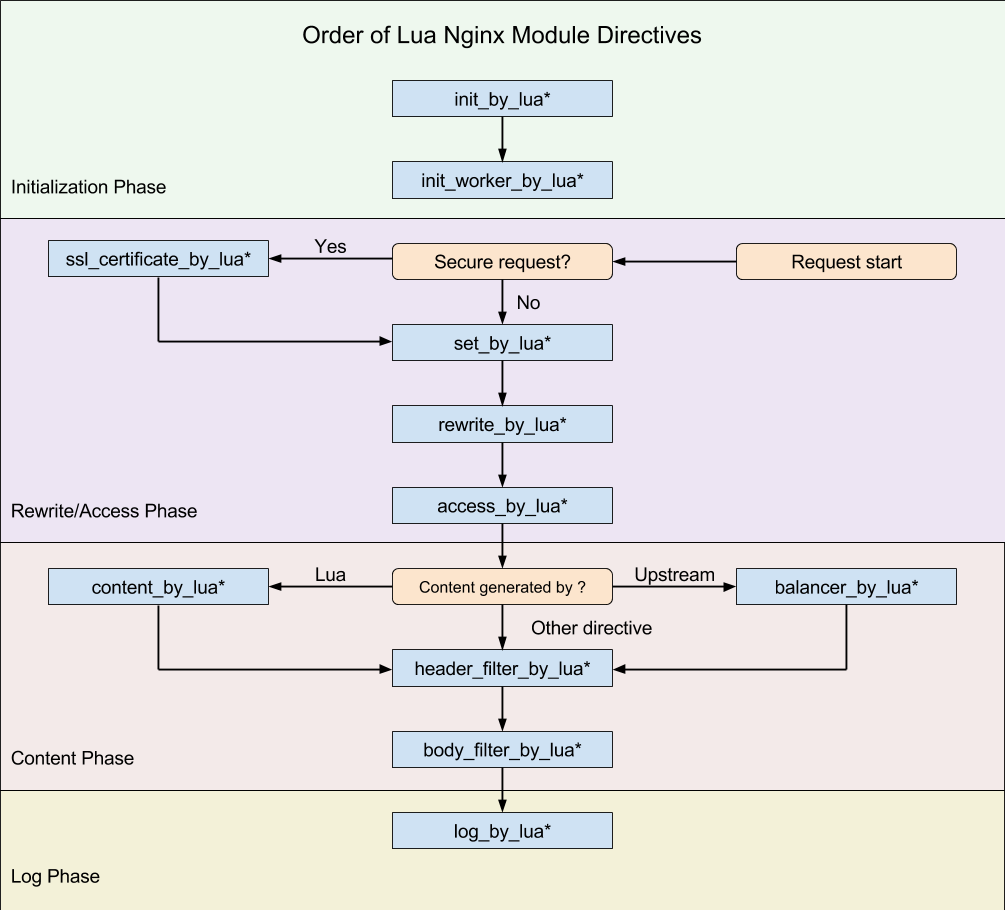
对比这些阶段,再看 Kong 框架的入口文件,就容易理解的多了:
init.lualocal Kong = {} -- init_by_lua_block -- 用来完成耗时长的模块加载 -- 或者初始化一些全局常量 function Kong.init() end -- init_worker_by_lua_block -- 用于定时拉取配置/数据(启动一些定时任务) -- 有几个Nginx工作进程就有几个定时任务 function Kong.init_worker() end -- ssl_certificate_by_lua_block -- 在Nginx和下游服务开始一个SSL握手时处理 function Kong.ssl_certificate() end -- balancer_by_lua_block -- 上游服务器中的负载均衡器 function Kong.balancer() end -- rewrite_by_lua_block -- 内部URL重写或者外部重定向 function Kong.rewrite() end -- access_by_lua_block -- 访问控制 function Kong.access() end -- header_filter_by_lua_block -- 设置响应头 function Kong.header_filter() end -- body_filter_by_lua_block -- 对响应数据进行过滤 function Kong.body_filter() end -- log_by_lua_block -- 使用Lua处理日志 function Kong.log() end -- content_by_lua_block function Kong.handle_error() end -- content_by_lua_block -- 提供AdminAPI功能 function Kong.serve_admin_api(options) end return Kong
Nginx 在启动后,会有一个 master 进程和多个相互独立的 worker 进程
Kong 的代码运行于 worker 进程,数据存储在数据库,同时在缓存中保留一份
当数据被修改时,需要通知给本地的其他 worker 进程和其他机器上的 worker 进程
其他 worker 接收事件后,删除缓存中对应的数据。下次从缓存读数据时发现没有的话,就从数据库加载出来。
事件分为本地事件和集群事件。本地事件用于通知在一台机器上的 worker,集群事件用于通知在多台机器上的 worker
本地事件-共享内存
Kong 实现了一套基于 Nginx 共享内存的事件发布-订阅(PUB/SUB)机制
- post_local() 方法在 worker 进程内进行事件发布
- post() 方法在同属于一台机器上的 worker 进程间进行事件发布
这 2 个方法需要指定 source 和 event 来确定事件源。
数据访问层封装了 insert、update 和 delete 3 个对数据操作的方法,分别会使用 post_local() 发出 event 对应增、删、改的事件
事件的数据格式如下:
{
schema = self.schema, --表名
operation = "create", --操作类型
entity = res, --数据
}worker 启动的时候会在 init_worker 阶段注册这些事件的订阅方法,见 worker_events.register()
订阅方法中把所有的 dao:crud 事件按表名称使用 post_local() 再进行分发,事件如下:
- source=crud, event=api
这个事件会通知 apis 数据的修改
这里对缓存中对 key 为 api_router:version 进行 invalidate 操作会发送一条 channel=invalidations 集群事件
- source=crud, event=routes
这个事件会通知 routes 数据的修改
这里对缓存中对 key 为 router:version 进行 invalidate 操作会发送一条 channel=invalidations 集群事件
source=crud, event=services
这个事件会通知 services 数据的修改
只有当不是新增和删除操作时才需要更新路由,因为新增时服务还是空的,下面没有路由,删除时只有没有路由时才能删除
对缓存中对 key 为router:version进行 invalidate 操作会发送一条 channel=invalidations 集群事件source=crud, event=targets
这个事件会通知 targets 数据的修改
使用cluster_events:broadcast方法发送一条 channel=balancer:targets 集群事件source=crud, event=upstreams
这个事件会通知 upstreams 数据的修改
使用cluster_events:broadcast方法发送一条 channel=balancer:upstreams 集群事件
集群事件-数据库
集群事件通过数据库实现。表 cluster_events 存放用于集群间分发的事件,表结构如下:
CREATE TABLE cluster_events (
id varchar(64) NOT NULL,
-- 标识生成事件的节点id
node_id varchar(64) NOT NULL,
-- 事件产生时间,精确到毫秒
at timestamp(3) NOT NULL,
-- 事件生效时间,精确到毫秒
nbf timestamp(3) NULL DEFAULT NULL,
-- 事件过期时间,精确到毫秒
expire_at timestamp(3) NOT NULL,
-- 事件类型
channel varchar(1023) DEFAULT NULL,
-- 事件数据
data varchar(10000) DEFAULT NULL,
PRIMARY KEY (id),
KEY cluster_events_at_idx (at),
KEY cluster_events_channelt_idx (channel)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;channel 的类型有:
- invalidations
表示路由规则、插件配置的变更
- balancer:targets
表示负载均衡的 targets 列表发生变更
- balancer:upstreams
表示 upstream 对象发生变更
- balancer:post_health
表示 target 的健康状态发生变更。由于被动健康检查拉出实例后,kong 不会在对该实例进行自动拉入,需要通过该事件来拉入实例。
调用 cluster_events:broadcast() 方法会往 cluster_events 表中新增一条记录
在 init_worker 阶段通过调用 cluster_events:subscribe() 会开启一个定时器,定时查询出表中新增的记录
这里要注意的是同一台机器上只会有一个 worker 进程会对数据库进行查询(通过加锁实现,代码见 get_lock()),查询出来后再通过共享内存的方式通知给这台机器上的其他 worker
配置参数 db_update_frequency 确定查询数据库的间隔,默认为 5 秒。数据范围根据 at 字段是否落在 (起始时间, 结束时间] 确定。起始时间第一次设置在 init_worker 阶段,调用 ngx.now() 获取当前时间(精确到毫秒)并放入 key 为 cluster_events:at 的共享内存中。
之后抢到锁的 worker 会从共享内存中取出该时间,该时间需要减去 db_update_propagation + 0.001 来确定起始时间,以防止事件丢失。配置参数 db_update_propagation 默认为 0。结束时间取 ngx.now() 的值。
查询成功后会把结束时间覆盖之前的起始时间,并把该事件分发到本机的其他 worker
对于设置了 nbf 的事件,kong 如果发现还没到生效时间,就会通过 ngx.timer 设置一个定时器延后分发该事件。